
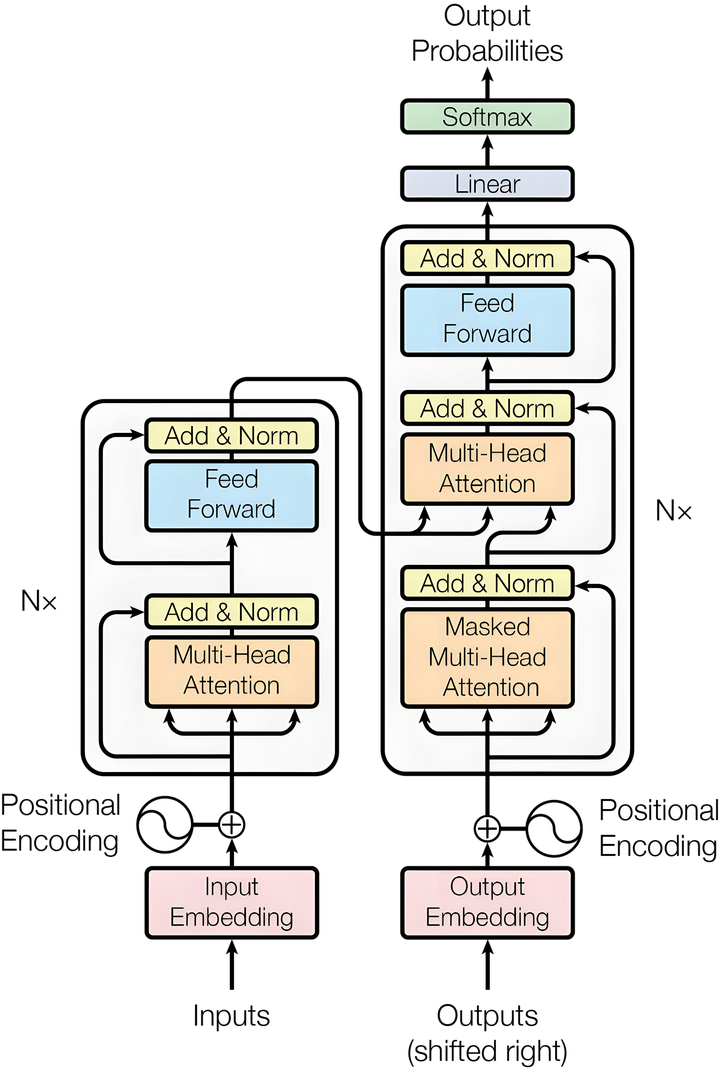
<span style="color:#d14;font-weight:bold">Transformer</span>
Transformer 架构
分词(Tokenization)
目标:将一串连续的、人类可读的自然语言文本,切分成一个个模型能够理解的“单元”,并为每个单元分配一个唯一的数字 ID 。
1. 选择分词器(Tokenizer)
现代 Transformer (如 BERT , GPT )通常使用子词分词法( Subword Tokenization ),例如 WordPiece ( BERT )、 Byte-Pair Encoding (BPE)( GPT )、 SentencePiece 等。
这种方法的好处是能很好地平衡词汇表大小与未登录词( OOV )问题。它可以将陌生长词拆分成已知的、更小的子词甚至字符。
2.执行分词
例如,使用 BERT 的 WordPiece 分词器对句子进行分词:
-
原始文本: “I love natural language processing.”
-
分词后: [“I”, “love”, “natural”, “language”, “processing”, “.”]
-
对于一些语言或复杂词,可能会被进一步拆分:
- “unhappiness” -> [“un”, “##happiness”] (##表示此前缀需要与前一个 token 连接)
- “playing” -> [“play”, “##ing”]
3.映射到 ID
每个分词器内部都维护着一个词汇表( Vocabulary ),这是一个从 Token 字符串到唯一 ID (整数)的映射。
将上一步得到的 Token 序列转换为 ID 序列:
- [“I”, “love”, “natural”, “language”, “processing”, “.”] -> [101, 2342, 12345, 3456, 5678, 102]
额外处理
通常会添加一些特殊 Token :
-
[CLS]:位于序列开头,用于分类任务的总表示。
-
[SEP]:用于分隔两个句子(例如在问答或自然语言推理任务中)。
-
[PAD]:用于将不同长度的序列填充到相同的长度。
所以最终的 ID 序列可能是:[[CLS], 101, 2342, 12345, 3456, 5678, 102, [SEP], [PAD], [PAD]]
至此,文本已经变成了一个数字序列,但计算机还不能理解这些数字的“含义”。
嵌入(Embedding)
目标:将每个表示“符号”的 ID 数字,转换为一个稠密的、低维的、蕴含语义信息的向量(即词向量)
1. 嵌入层( Embedding Layer )
模型内部有一个可学习的矩阵,称为嵌入矩阵( Embedding Matrix )。它的尺寸是 (词汇表大小 V, 模型维度 d_model)。
- 例如,词汇表有 30000 个词,模型维度是 768 ,那么这个矩阵的大小就是 30000 x 768 。
这个矩阵的每一行都对应词汇表中一个 ID 所代表的 Token 的向量。
2. 查找( Lookup )
嵌入过程实际上是一个**查找表( Lookup Table )**操作。
对于上一步得到的 ID 序列 [101, 2342, 12345, …],我们拿着每个 ID 作为索引,去嵌入矩阵中找到对应的第 101 行、第 2342 行、第 12345 行…。
这样,每个 ID 都被转换为了一个 d_model 维的向量(比如 768 维)。
假设 d_model = 4 (实际中更大),那么转换可能如下:
-
ID: 101 -> [0.2, -1.5, 0.8, 1.0]
-
ID: 2342 -> [1.2, 0.5, -0.3, -1.2]
至此,我们得到了一个向量序列,其形状为(序列长度 L, 模型维度 d_model)。这个序列已经包含了 Token 的语义信息(因为嵌入矩阵是在训练过程中从数据中学到的)。
位置编码 (Positional Encoding)
问题: Transformer 的自注意力机制本身是置换不变( Permutation Invariant ) 的,它无法感知 Token 在序列中的顺序信息。"猫吃鱼" 和 "鱼吃猫" 对它来说是一样的。
解决方案:将每个 Token 的位置信息注入到输入向量中。
为什么需要位置编码?
自注意力在数学上对序列的排列是“置换不敏感”的;若不额外提供位置信息,“猫吃鱼”和“鱼吃猫”对模型很可能等价。因此在输入端或注意力打分阶段注入位置线索,让模型区分顺序。
1. 生成位置信息
为序列中的每个位置( 0, 1, 2, …, L-1 )也生成一个与词向量维度相同的向量( d_model 维)。这个向量包含了该位置的绝对或相对位置信息。
-
原始 Transformer 使用一种固定的、基于正弦和余弦函数的编码方式( Sinusoidal Positional Encoding )。
-
许多现代 Transformer (如 BERT , GPT ) 则使用可学习的位置编码( Learned Positional Embedding ),即把位置也当作一个需要学习的嵌入层。位置 0 对应一个向量,位置 1 对应另一个向量,以此类推。
2. 相加融合
将每个 Token 的词向量与其对应的位置编码向量按元素相加。
最终输入向量 = 词向量 + 位置编码向量
这个过程可以形象地理解为:给每个词向量“染上”了它在句子中位置的颜色。
总结:最终的输入向量 x
经过以上三步,我们得到了 Transformer 编码器( Encoder )第一层的真正输入 x :
-
它是一个形状为 (序列长度 L, 模型维度 d_model) 的矩阵。
-
矩阵中的每一行对应一个 Token ,这个 Token 的向量既包含了它的语义信息(来自 Embedding ),也包含了它的位置信息(来自 Positional Encoding )。
这个 x 矩阵随后就会被送入 Transformer 的多头自注意力层和前馈神经网络层进行深层的特征提取和计算。
简单比喻:
-
分词:把一篇文章拆分成一个个单独的“乐高积木块”( Tokens ),并给每个积木块贴上一个编号( ID )。
-
嵌入:根据编号,从一个盒子里找到对应的积木块,这个积木块本身有颜色和形状(向量),代表了它的含义。
-
位置编码:根据这个积木块在整体模型中的位置(第几个),给它贴上一个小标签或涂上一点特殊的颜色,标明它应该放在哪里。
-
输入向量 x :最终,你手上拿着的就是一块既知道“自己是什么”(语义),又知道“自己该在哪”(位置)的准备好被组装(计算)的积木块。
A. 示例:分词 → ID → 嵌入 → + 位置( ASCII 示意)
1 | "I love NLP." |
Encoder Layer
经过准备的输入数据 now 被送入一个个编码器层。每个层都由两个核心子层构成
多头自注意力机制 (Multi-Head Self-Attention)
这是 Transformer 最伟大、最核心的思想
自注意力 (Self-Attention)
-
核心思想: 让序列中的每个词都“环顾四周”,看看其他词,然后根据其他词的重要性来重新塑造自己的表示。
-
例如:你在派对上听到有人说“它真可爱,一直在玩那个闪亮的球”,你的大脑会瞬间做注意力计算:
- 查询 (Query): 你听到“它”,想知道“它”指什么
- 键 (Key): 你回想之前听到的所有词:“好奇的”、“猫”、“追”、“闪亮的”、“球”。
- 值 (Value): 这些词本身的信息
-
你发现“它”和“猫”的关联性(相似度)最高,于是你得出结论:“它”很可能指的是“猫”。这个过程就是自注意力,你通过关注其他词(“猫”)来更新了对“它”的理解。
计算过程如下:
-
创建 Q ( Query ), K ( Key ), V ( Value )向量
对于输入序列中的每个单词(由其嵌入向量 x_i 表示),我们需要将其转换为三个不同的向量: Q 查询向量( Query )、 K 键向量( Key ) 和 V 值向量( Value )
如何创建?
通过将单词的嵌入向量 x_i 与三个在训练过程中学习得到的权重矩阵 W^Q, W^K, W^V 相乘。- Q = x_i . w_q
- K = x_i . w_k,
- V = x_i . w_v

-
计算注意力分数( Attention Scores )
现在,假设我们正在计算第一个单词 “ Thinking ” 的自注意力。我们需要评估输入序列中每个单词与 “ Thinking ” 的相关性。这个相关性通过注意力分数来衡量
如何计算? 取当前单词的查询向量( q ₁) 与序列中所有单词的键向量( k ᵢ) 依次进行点积(Dot Product)
- 分数₁ = q ₁ · k ₁ (“ Thinking ” 与自身的分数)
- 分数₂ = q ₁ · k ₂ (“ Thinking ” 与 “ Machines ” 的分数)
点积运算的结果越大,表示两个向量的相关性越高。
 -
缩放(scale)
将上一步得到的分数除以一个常数(通常是键向量维度 d_k 的平方根,在您的例子中是 √ 64 = 8 )。这是为了在反向传播时拥有更稳定的梯度。当 d_k 很大时,点积的结果可能非常大,导致 softmax 函数的梯度消失
-
应用 Softmax
将缩放后的分数通过 Softmax 函数
Softmax 有两个作用:- 将所有分数归一化,使得它们均为正数且总和为 1
- 强化最高分数,抑制低分数
这些 Softmax 后的结果就是注意力权重。它代表了在编码“ Thinking ”这个位置时,应该给予其他每个位置的关注程度。

-
加权求和得到输出
- 加权( Weight ):将每个单词的值向量( v ᵢ) 乘以上一步得到的对应的注意力权重。这背后的直觉是:保留我们想要重点关注的那个单词的完整值向量,而淹没不相关的单词(通过乘以一个极小的权重)。
- 求和( Sum ):将第五步中所有加权后的值向量求和。这个求和后的结果向量就是自注意力机制在当前位置(对于单词“ Thinking ”)的输出( z ₁)。它是一个包含了序列中所有相关单词信息的全新表示.

矩阵形式的计算
- 计算 Q, K, V 矩阵
将整个输入序列的嵌入向量打包成矩阵 X (形状为 (序列长度, d_model)),然后一次性乘以其对应的权重矩阵。
 - 合并计算步骤

掩码自注意力
为什么需要掩码
想象一下,你正在参加一场开卷考试,规则非常奇特:
1.普通自注意力:考试的规则是,你可以翻阅整本教科书(包括后面的答案)来回答任何一个问题。这当然能让你考高分,但这也是一种“作弊”,因为你提前知道了所有信息
2.掩码自注意力:现在规则变了。当你回答第 3 题时,你只能看书的前 3 章;回答第 5 题时,你只能看书的前 5 章。你无法看到未来的章节。这迫使你只能根据当前及之前出现的信息来推理和预测。
掩码主要有两个目的:
- 防止信息泄露(用于解码器):在训练时,我们需要防止模型在预测序列中的第 t 个位置时,“偷看”到 t+1 及之后位置的真实答案(即未来信息)。掩码确保了这种“作弊”不会发生,让模型只能基于已生成的内容进行预测。这被称为 因果掩码( Causal Masking ) 或 前瞻掩码( Look-ahead Masking )。
- 处理变长序列(用于编码器和解码器):在实际批次训练中,句子长度不同。短的句子需要被 填充( Padding ) 到和最长句子一样的长度。这些填充 token (通常是
)是无意义的。我们需要用一个 填充掩码( Padding Mask ) 来告诉模型:“忽略这些填充位置,不要在这些位置上计算注意力”。
为什么需要掩码
想象一下,你正在参加一场开卷考试,规则非常奇特:
1.普通自注意力:考试的规则是,你可以翻阅整本教科书(包括后面的答案)来回答任何一个问题。这当然能让你考高分,但这也是一种“作弊”,因为你提前知道了所有信息
2.掩码自注意力:现在规则变了。当你回答第 3 题时,你只能看书的前 3 章;回答第 5 题时,你只能看书的前 5 章。你无法看到未来的章节。这迫使你只能根据当前及之前出现的信息来推理和预测。
1.因果掩码( Causal Mask )
让我们回到那个简单的例子,句子是:[“ I ”, “ like ”, “ cats ”]
在训练阶段,我们已知整个目标序列(比如翻译结果 “ Je like les chats ”)。但如果模型在预测第二个词 “ like ” 时,就看到了第三个词 “ chats ” 的信息,那训练就失去了意义,因为模型在推理时(生成时)是看不到未来的词的
如何实现?
- 1.计算注意力分数:首先,我们像正常一样计算 Query 和 Key 的点积,得到一个注意力分数矩阵。
| ----- | ----- |
|---|---|
|  |  |
-
2.应用掩码矩阵:然后,我们加上(或者说“盖上”)一个掩码矩阵。这个掩码矩阵上三角部分(不包括对角线) 的值是一个极大的负数(如 -1e9 ),而其他位置是 0 。
- 为什么是极负数? 因为之后我们要做 Softmax : Softmax(很大负数) ≈ 0 。这样,被掩码的位置的注意力权重就会几乎为
| Token | I | like | cats |
|---|---|---|---|
| ------- | — | ------ | ------ |
| I | 分数 | -inf | -inf |
| like | 分数 | 分数 | -inf |
| cats | 分数 | 分数 | 分数 |
- 对于 “ I ”(位置 0 ):只能关注到位置 0 (自己)。
- 对于 “ like ”(位置 1 ):可以关注到位置 0 和 1 ,但不能关注位置 2 ( cats )。
- 对于 “ cats ”(位置 2 ):可以关注到所有位置( 0, 1, 2 )
- 计算权重和输出:对这个掩码后的分数矩阵进行 Softmax 和加权求和。现在,每个位置的输出向量 Z 都只包含了来自它之前及自身位置的信息。

这个过程确保了模型在预测下一个词时,只会依赖于它已经“写出来”的词,从而能够被正确地训练用于生成任务。
2.填充掩码( Padding Mask )
假设我们有一个批次( Batch )包含两个句子:
- Sentence 1: [“ I ”, “ like ”, “ cats ”,
, ] (实际长度=3 ,填充到 5) - Sentence 2: [“ He ”, “ runs ”,
, , ] (实际长度=2 ,填充到 5)
我们希望模型忽略所有的token 。
如何实现?
我们同样使用一个掩码矩阵,但逻辑与因果掩码不同。
1.创建 Padding Mask 向量:我们通常会有一个注意力掩码( attention_mask ),其形状为 (batch_size, seq_len)。实际词的位置为 1 ,填充位置为 0 。
- For Batch: attention_mask = [[1, 1, 1, 0, 0], [1, 1, 0, 0, 0]]
2.应用到注意力分数:我们需要将这个向量扩展成一个可以和注意力分数矩阵相加的形状。
-
将 attention_mask 扩展为 (batch_size, 1, 1, seq_len)。 1 的维度是为了方便广播( Broadcasting )。
-
然后,我们创建一个“反向”掩码: mask = (attention_mask == 0)。即填充位置是 True (或 1 ),实际位置是 False (或 0 )。
-
最后,我们执行: attention_scores = attention_scores.masked_fill(mask, -1e9)。这会将所有 mask 为 True 的位置(即填充位置)的值替换为 -1e9 。
这样,在计算注意力时,模型就不会从那些无意义的
在实际应用中,因果掩码和填充掩码通常会叠加使用!
多头自注意力
想象一下,你正在阅读一本非常复杂的小说,里面有很多人物和错综复杂的关系。现在,你想彻底理解其中一句话,比如:
“哈利对赫敏施了一个咒语,因为她弄坏了他的魔杖,但罗恩觉得这很酷。”
为了完全理解这句话,你的大脑会本能地做以下几件事:
- 聚焦关键词:你会注意到“哈利”、“赫敏”、“罗恩”、“咒语”、“魔杖”这些核心词
- 分析关系:
- 谁对谁:哈利 -> 赫敏(施咒语)
- 为什么:因为赫敏 -> 哈利的魔杖(弄坏了)
- 谁怎么看:罗恩 -> 哈利的行为(觉得酷)
- 多角度分析:你可能会从情感角度(赫敏可能感到愧疚)、因果角度(弄坏魔杖是起因)、人物性格角度(罗恩喜欢冒险)等多个层面来理解这句话
多头自注意力机制就是让计算机模仿这个“多角度分析”过程
-
自注意力( Self-Attention ):让句子中的每个词都去“看”一遍句子中的所有其他词(包括自己),并思考:“我和你们每个人的关联程度是多少?”然后根据这些关联程度,重新调整自己的“价值( Value )”。
-
多头( Multi-Head ):我们不只做一次这种“看”的操作,而是同时进行很多次(多个头)。每个“头”就像一个专注于不同方面的“专家”。
- 头 A (语法专家):可能更关注谁对谁做了什么(动词与主语、宾语的关系)。
- 头 B (情感专家):可能更关注情感词(“酷”是积极的,“弄坏”是消极的)。
- 头 C (指代专家):可能更关注代词指代(“他”指的是哈利,“她”指的是赫敏)。
最后,我们把所有专家的分析结果汇总起来,得到对这句话更丰富、更立体的理解
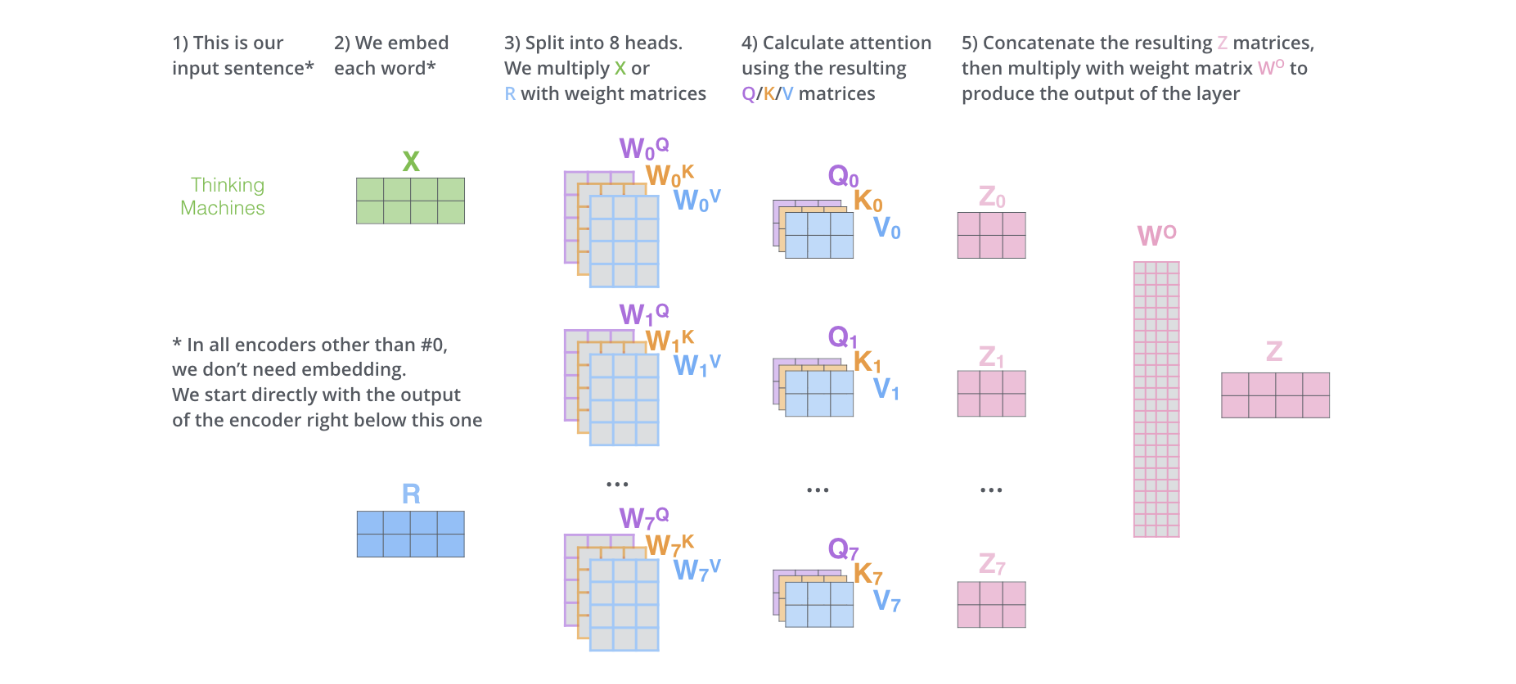
数学公式详解
- 输入投影到多个子空间
对于每个头 i(i = 1, 2, …, h),我们有独立的投影矩阵:
Q_i = X.Wq_i
K_i = X.Wk_i
V_i = X.Wv_i
W 矩阵的维度是[d_model,d_k],d_k 通常为 d_model // h(head) - 每个头独立计算注意力
 - 拼接所有头的输出
 - 最终线性投影

